
Data-loading engine
Gato GraphQL gebruikt server-side componenten om het datamodel te representeren (geen grafen of bomen). Laten we bekijken hoe het het data-laadproces uitvoert om de GraphQL-query op te lossen.
Om de gegevens te verwerken, moeten we de componenten platslaan naar types (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), ze ordenen zoals ze verschenen in de componenthierarchie (Director, dan Film, dan Actor) en ze verwerken in "iteraties", waarbij we de objectgegevens per type ophalen in zijn eigen iteratie, als volgt:

De data-loading engine van de server moet het volgende (pseudo-)algoritme implementeren om de gegevens te laden:
Voorbereiding:
- Maak een lege wachtrij aan om de lijst met ID's op te slaan van de objecten die uit de database opgehaald moeten worden, georganiseerd per type (elke invoer is:
[type => lijst van ID's]) - Haal het ID op van het featured director-object en plaats het in de wachtrij onder type
Director
Herhaal totdat de wachtrij leeg is:
- Haal het eerste item uit de wachtrij: het type en de lijst met ID's (bijv.:
Directoren[2]), en verwijder dit item uit de wachtrij - Voer met behulp van het
TypeDataLoader-object van het type één enkele query uit op de database om alle objecten voor dat type met die ID's op te halen - Als het type relationele velden heeft (bijv.: type
Directorheeft relationeel veldfilmsvan typeFilm), verzamel dan alle ID's uit die velden van alle objecten die in de huidige iteratie zijn opgehaald (bijv.: alle ID's in veldfilmsvan alle objecten van typeDirector), en plaats deze ID's in de wachtrij onder het bijbehorende type (bijv.: ID's[3, 8]onder typeFilm).
Aan het einde van de iteraties hebben we alle objectgegevens voor alle types geladen, als volgt:
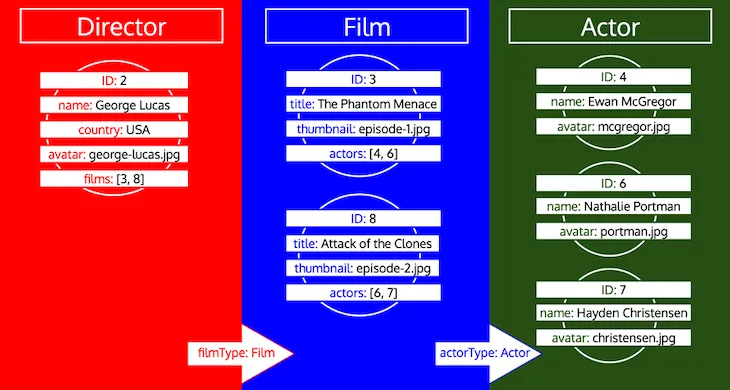
Let op hoe alle ID's voor een type worden verzameld totdat het type in de wachtrij wordt verwerkt. Als we bijvoorbeeld een relationeel veld preferredActors toevoegen aan type Director, worden deze ID's toegevoegd aan de wachtrij onder type Actor en worden ze samen verwerkt met de ID's uit het veld actors van type Film:
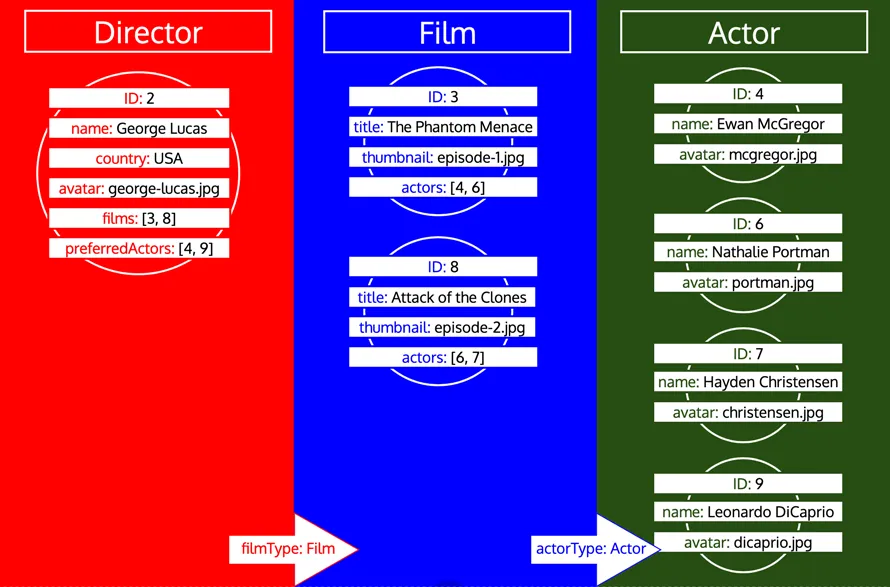
Als een type echter al is verwerkt en we daarna meer gegevens van dat type moeten laden, is dat een nieuwe iteratie op dat type. Als we bijvoorbeeld een relationeel veld preferredDirector toevoegen aan het type Author, wordt type Director opnieuw aan de wachtrij toegevoegd:
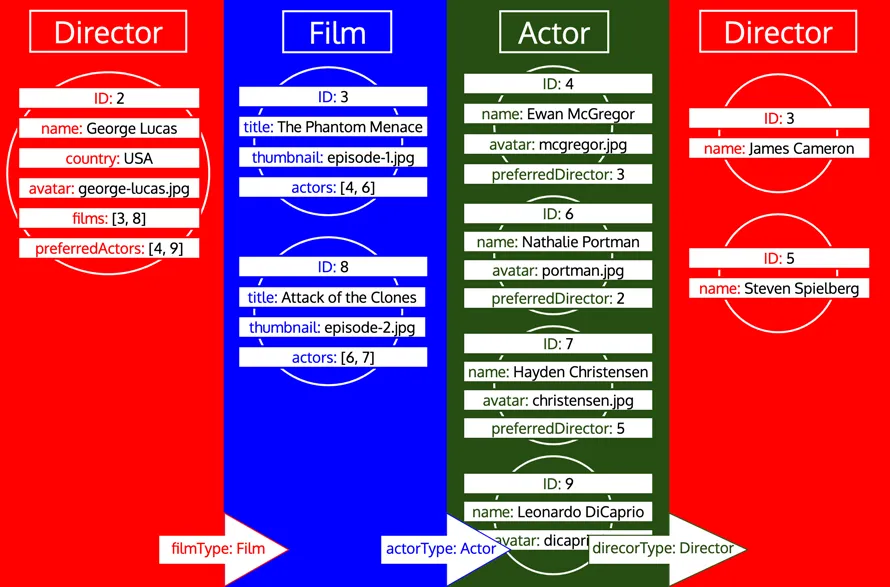
Nu we alle objectgegevens hebben opgehaald, moeten we deze vormen naar de verwachte respons, waarbij de GraphQL-query gespiegeld wordt. Zoals te zien is, hebben de gegevens echter niet de vereiste boomstructuur. In plaats daarvan bevatten relationele velden de ID's naar het geneste object, waarmee de manier waarop gegevens worden weergegeven in een relationele database wordt nagebootst. Volgen we deze vergelijking, dan kunnen de gegevens die per type zijn opgehaald worden weergegeven als een tabel, als volgt:
Tabel voor type Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabel voor type Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabel voor type Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Met alle gegevens georganiseerd als tabellen, en wetende hoe elk type zich verhoudt tot de andere (d.w.z. Director verwijst naar Film via veld films, Film verwijst naar Actor via veld actors), kan de GraphQL-server de gegevens eenvoudig omzetten naar de verwachte boomvorm:
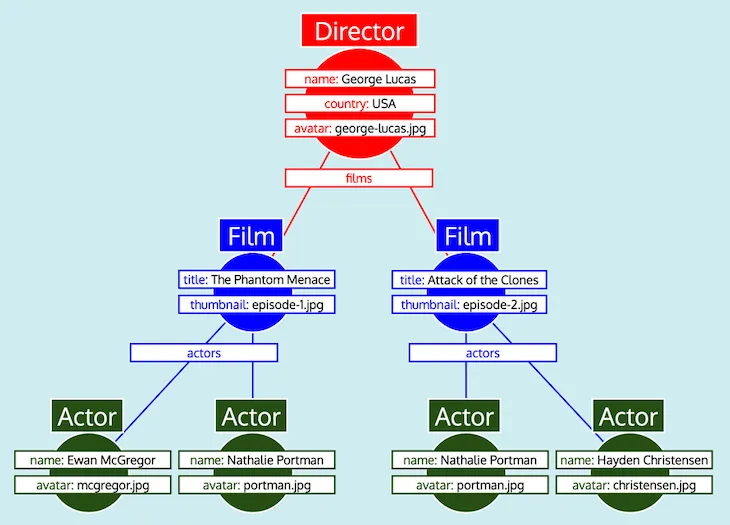
Tot slot geeft de GraphQL-server de boom terug, die de vorm heeft van de verwachte respons:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analyse van de tijdcomplexiteit van de oplossing
Laten we de big O-notatie van het data-laadalgoritme analyseren om te begrijpen hoe het aantal queries dat op de database wordt uitgevoerd groeit naarmate het aantal invoergegevens toeneemt, zodat we zeker weten dat deze oplossing performant is.
De data-loading engine laadt gegevens in iteraties die overeenkomen met elk type. Wanneer een iteratie begint, heeft de engine al de lijst van alle ID's van alle op te halen objecten, zodat het één enkele query kan uitvoeren om alle gegevens voor de bijbehorende objecten op te halen. Hieruit volgt dat het aantal queries naar de database lineair groeit met het aantal types dat betrokken is bij de query. Met andere woorden, de tijdcomplexiteit is O(n), waarbij n het aantal types in de query is (als een type echter meer dan één keer wordt geïtereerd, moet het meer dan één keer worden meegeteld in n).
Deze oplossing is zeer performant, veel beter dan de exponentiële complexiteit die verwacht wordt bij het werken met grafen, of de logaritmische complexiteit die verwacht wordt bij het werken met bomen.
Geïmplementeerde PHP-code
Het data-laadproces vindt plaats in de functie getComponentData van klasse Engine in het pakket Component Model.