
Directive-pipeline
Directives worden in een pipeline geplaatst en in volgorde uitgevoerd. Het oorspronkelijke ontwerp is eenvoudig, zoals dit:

In deze architectuur:
- De invoer van de pipeline is de waarde van het veld, geleverd door de veld-resolver
- Elke directive voert zijn logica uit en geeft het resultaat door aan de volgende directive in de pipeline
- De uitvoer van de pipeline is de opgeloste veldwaarde, nadat alle directives deze hebben verwerkt
Deze architectuur maakt echter niet het maximale gebruik van GraphQL. Hieronder staat de beschrijving van alle stadia van de werkelijke directive-pipeline, tot het uiteindelijke ontwerp zoals geïmplementeerd in Gato GraphQL.
Directives als bouwstenen van de query-oplossing
In eerste instantie zouden we kunnen overwegen om de GraphQL-server het veld via een bepaald mechanisme te laten oplossen, en deze waarde vervolgens als invoer door te geven aan de directive-pipeline.
Het is echter veel eenvoudiger om één enkel mechanisme te hebben dat alles afhandelt: het aanroepen van veld-resolvers (zowel voor het valideren als het oplossen van velden) kan al via de directive-pipeline worden gedaan. In dit geval is de directive-pipeline het enige mechanisme dat wordt gebruikt om de query op te lossen.
Om deze reden wordt de Gato GraphQL-server voorzien van twee speciale directives:
@validateroept de veld-resolver aan om te controleren of het veld opgelost kan worden (bijv.: de syntaxis is correct, het veld bestaat, etc.)- Als dit succesvol is, roept
@resolveValueAndMergede veld-resolver aan om het veld op te lossen en de waarde samen te voegen in het antwoordobject
Deze twee zijn van het speciale type "systeem"-directives: ze zijn voorbehouden aan de GraphQL-engine en zijn impliciet aanwezig op elk veld. (In tegenstelling hiermee zijn standaard directives expliciet: ze worden door de gebruiker aan de query toegevoegd.)
Door gebruik te maken van deze twee directives wordt deze query:
query {
field1
field2 @directiveA
}...opgelost als deze:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}De pipeline ziet er nu zo uit (let op: de pipeline ontvangt het veld als invoer, niet de initieel opgeloste waarde):

Pipeline-slots
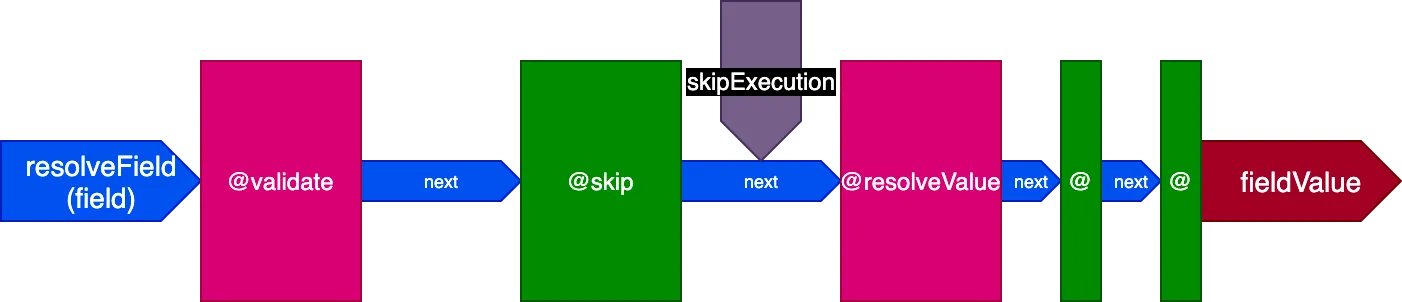
Directives worden normaal gesproken uitgevoerd na @resolveValueAndMerge, omdat ze hoogstwaarschijnlijk betrekking hebben op het bijwerken van de waarde van het opgeloste veld. Er zijn echter ook directives die vóór @validate moeten worden uitgevoerd, of tussen @validate en @resolveValueAndMerge.
Bijvoorbeeld:
- Om de tijd te meten die nodig is om een veld op te lossen, kan de directive
@traceExecutionTimede huidige tijd vóór en na het oplossen van het veld opvragen, door subdirectives@startTracingExecutionTimeaan het begin en@endTracingExecutionTimeaan het einde van de pipeline te plaatsen - Een directive
@cachemoet controleren of een gevraagd veld in de cache staat en dit antwoord al teruggeven, vóórdat@resolveValueAndMergewordt uitgevoerd
De pipeline biedt dan vijf verschillende slots via klasse PipelinePositions, en de directive geeft aan in welk slot hij moet worden uitgevoerd:
- Het slot
"beginning": helemaal aan het begin - Het slot
"before-validate": vóór de validatie - Het slot
"middle": na de validatie en vóór het oplossen van het veld - Het slot
"after-resolve": na het oplossen van het veld - Het slot
"end": helemaal aan het einde
De directive-pipeline ziet er nu zo uit (met slechts 3 stadia ter vereenvoudiging):

Let op hoe directives @skip en @include zo eenvoudig te ondersteunen zijn in deze architectuur: geplaatst in het slot "middle" kunnen ze directive @resolveValueAndMerge (samen met alle directives in latere stadia van de pipeline) laten weten dat deze niet moet worden uitgevoerd, door de vlag skipExecution op true te zetten.
Een directive uitvoeren op meerdere velden in één aanroep
Tot nu toe hebben we één veld beschouwd als invoer voor de directive-pipeline. In een typische GraphQL-query ontvangen we echter meerdere velden waarop directives moeten worden uitgevoerd.
In de onderstaande query wordt directive @upperCase bijvoorbeeld uitgevoerd op velden "field1" en "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Bovendien, omdat de GraphQL-engine systeemdirectives @validate en @resolveValueAndMerge aan elk veld in de query toevoegt, zodat deze query:
query {
field1
field2
field3
}...wordt opgelost als deze query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Zullen de systeemdirectives dus altijd alle velden als invoer ontvangen.
Als gevolg hiervan is de directive-pipeline zo opgezet dat hij meerdere velden als invoer ontvangt, en niet slechts één tegelijk:

Deze architectuur is efficiënter, omdat het uitvoeren van een directive slechts één keer voor alle velden sneller is dan het één keer per veld uitvoeren, met dezelfde resultaten.
Wanneer je bijvoorbeeld controleert of de gebruiker ingelogd is om toegang tot het schema te verlenen, kan de operatie slechts één keer worden uitgevoerd. De volgende code uitvoeren:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}is efficiënter dan deze code uitvoeren:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Dit lijkt misschien geen groot verschil bij het aanroepen van een lokale functie zoals isUserLoggedIn, maar het kan een groot verschil maken bij interactie met externe diensten, zoals bij het oplossen van REST-endpoints via GraphQL. In dergelijke gevallen kan het één keer uitvoeren van een functie in plaats van meerdere keren het verschil maken tussen wel of niet bepaalde functionaliteit kunnen bieden.
Laten we een voorbeeld bekijken. Bij interactie met Google Translate via een @translate-directive moet de GraphQL API een verbinding via het netwerk opzetten. Het uitvoeren van deze code is dan zo snel als het maar kan zijn:
googleTranslateFields([$field1, $field2, $field3]);Daarentegen zal het afzonderlijk en meerdere keren uitvoeren van de functie voor een hogere latentie zorgen, wat resulteert in een langere responstijd en de prestaties van de API verslechtert. Mogelijk is dit geen groot verschil bij het vertalen van 3 strings (waarbij het veld de te vertalen string is), maar voor 100 of meer strings zal het zeker impact hebben:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Bovendien kan het één keer uitvoeren van een functie met alle invoer een beter resultaat opleveren dan de functie voor elk veld afzonderlijk uitvoeren. Nogmaals Google Translate als voorbeeld: de vertaling zal nauwkeuriger zijn naarmate we meer data aan de dienst verstrekken.
Wanneer je bijvoorbeeld de onderstaande code uitvoert:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Bij de eerste afzonderlijke uitvoering kent Google de context van "fork" niet, dus het kan zowel antwoorden met fork als bestek, als een splitsing in de weg, of een andere betekenis. Als we echter in plaats daarvan uitvoeren:
googleTranslate(["fork", "road", "sign"]);Uit deze bredere hoeveelheid informatie kan Google afleiden dat "fork" verwijst naar de splitsing in de weg, en een nauwkeurige vertaling teruggeven.
Om deze redenen ontvangen de directives in de pipeline de invoervelden allemaal tegelijk, en kan elke directive de beste manier bepalen om zijn logica op deze invoer uit te voeren (één uitvoering per invoer, één uitvoering voor alle invoer samen, of iets daartussenin).
De pipeline ziet er nu zo uit:
Een enkele directive-pipeline uitvoeren voor de hele query
We hebben zojuist geleerd dat het zinvol is om meerdere velden per directive uit te voeren, maar dit werkt goed zolang alle velden dezelfde directives toegepast hebben. Wanneer de directives verschillend zijn, kan dit leiden tot grotere complexiteit waardoor de implementatie moeilijker wordt en een deel van de behaalde voordelen verloren gaat.
Laten we bekijken hoe dit gebeurt. Overweeg de volgende query:
query {
field1 @directiveA
field2
field3
}Deze directive is equivalent aan deze:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}In dit scenario hebben velden field2 en field3 dezelfde set directives, en field1 heeft een andere, dus we zouden 2 verschillende pipelines moeten genereren om de query op te lossen:
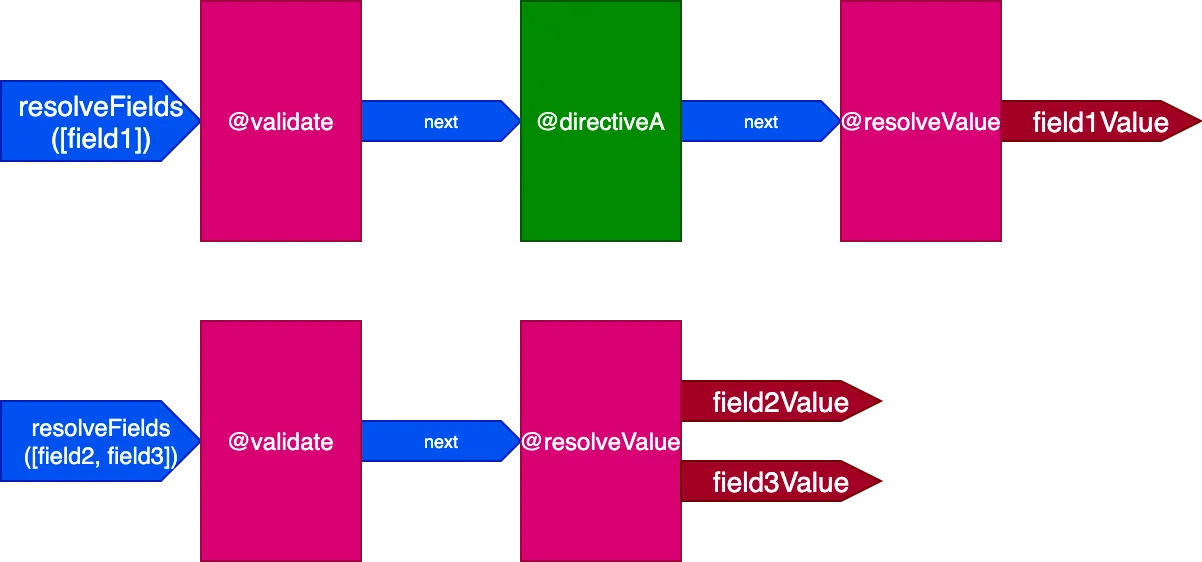
En wanneer alle velden een unieke set directives hebben, is het effect nog uitgesproken. Overweeg deze query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Die equivalent is aan deze:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}In deze situatie zullen we 3 pipelines hebben om 3 velden te verwerken, zoals dit:
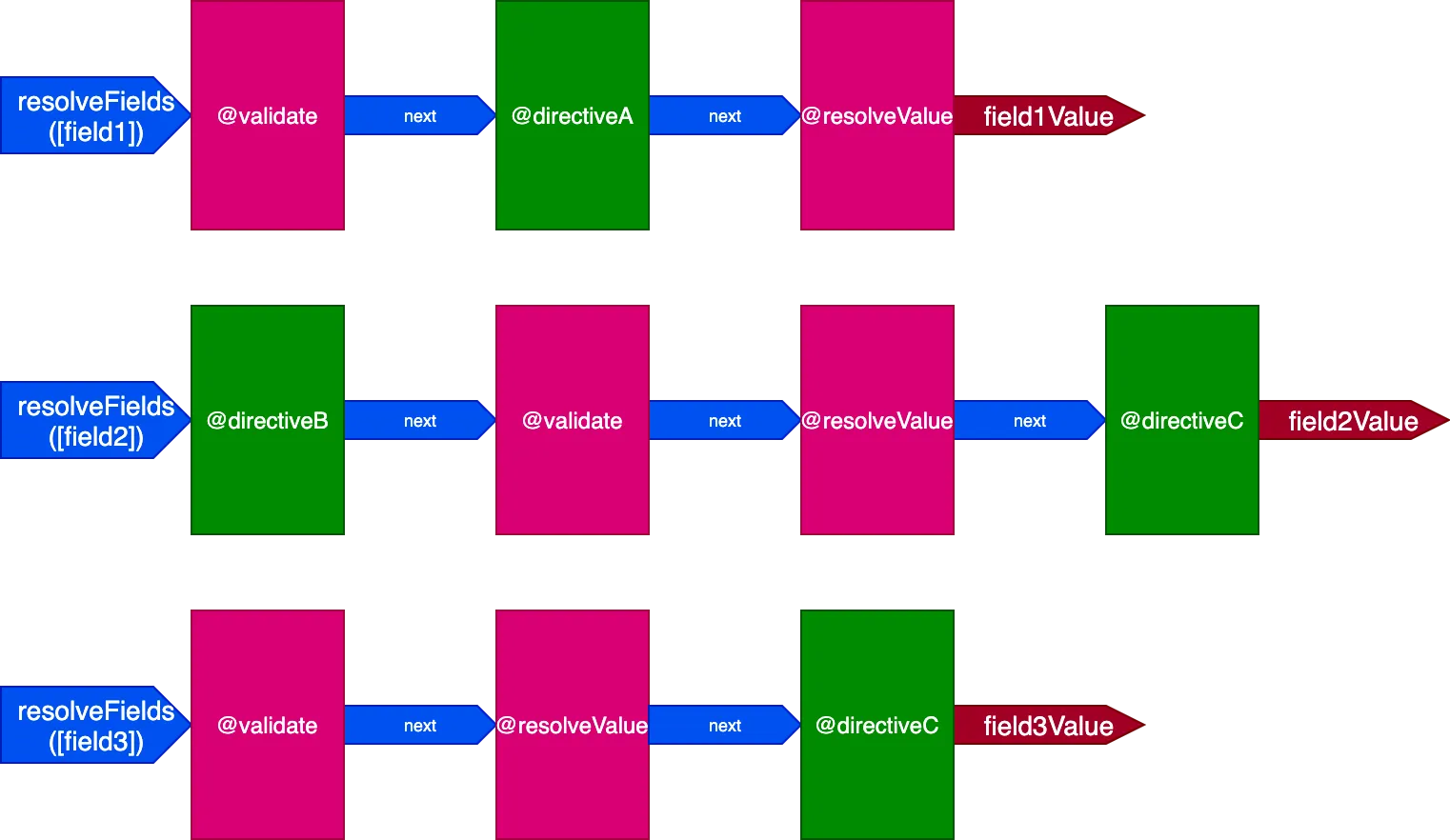
In dit geval, hoewel directives @validate en @resolveValueAndMerge op de 3 velden worden toegepast, omdat ze via 3 verschillende directive-pipelines worden uitgevoerd, zullen ze onafhankelijk van elkaar worden uitgevoerd, wat ons terugbrengt naar een situatie waarbij een directive één item tegelijk verwerkt.
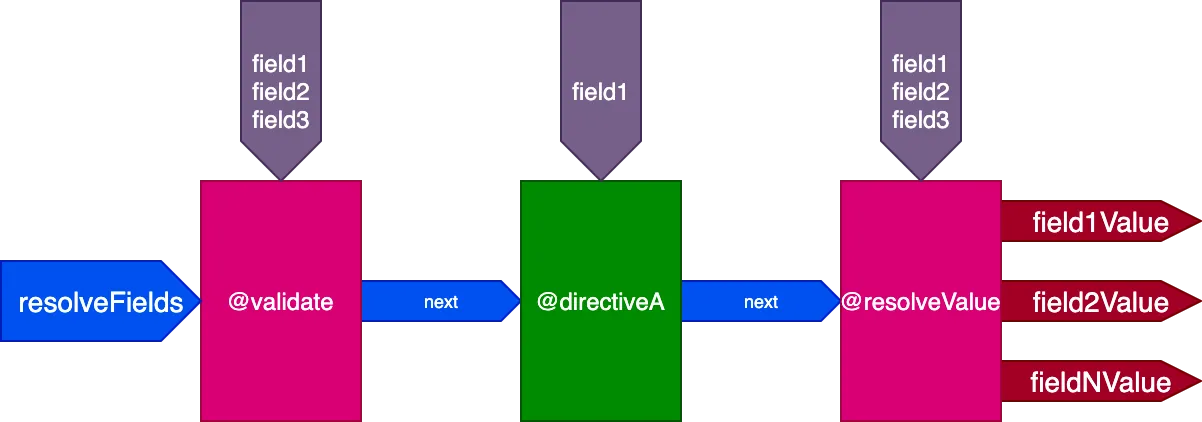
De oplossing voor dit probleem is om het aanmaken van meerdere pipelines te vermijden, en in plaats daarvan één enkele pipeline voor alle velden te gebruiken. Als gevolg hiervan geeft de engine de velden niet langer als invoer door aan de pipeline, omdat niet alle directives van één pipeline dezelfde set velden zullen verwerken; in plaats daarvan moet elke directive zijn eigen lijst van velden als eigen invoer ontvangen.
Dan krijgen voor deze query:
query {
field1 @directiveA
field2
field3
}...directives @validate en @resolveValueAndMerge alle 3 velden als invoer, en directiveA krijgt alleen "field1":
En voor deze query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...krijgen directives @validate en @resolveValueAndMerge alle 3 velden als invoer, directiveA krijgt alleen "field1", directiveB krijgt alleen "field2", en directiveC krijgt "field2" en "field3":
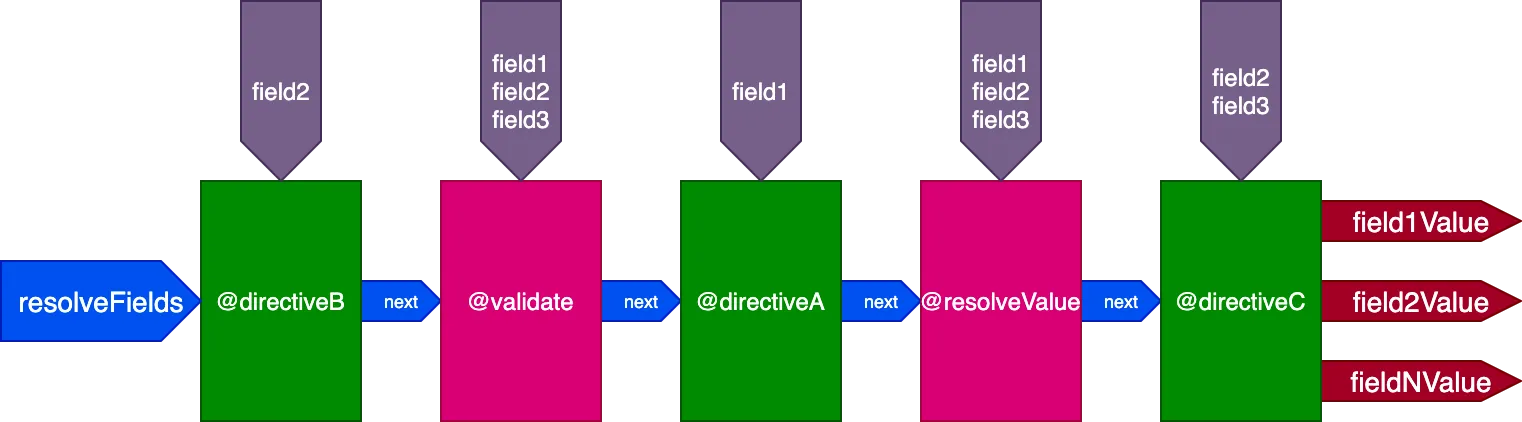
De directive-uitvoering ID voor ID beheren
Tot nu toe kon een directive in een bepaald stadium de uitvoering van directives in latere stadia beïnvloeden via een vlag skipExecution. Deze vlag is echter niet granuleerbaar genoeg voor alle gevallen.
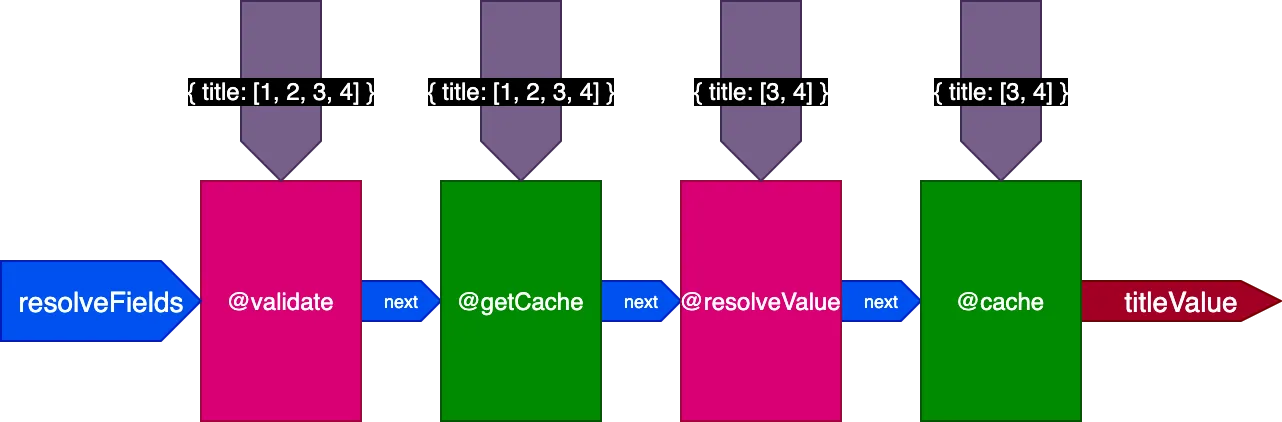
Overweeg bijvoorbeeld een directive @cache, die in het slot "end" is geplaatst om de veldwaarde op te slaan, zodat de volgende keer dat het veld wordt opgevraagd, de waarde uit de cache kan worden opgehaald via een directive @getCache die in het slot "middle" is geplaatst:
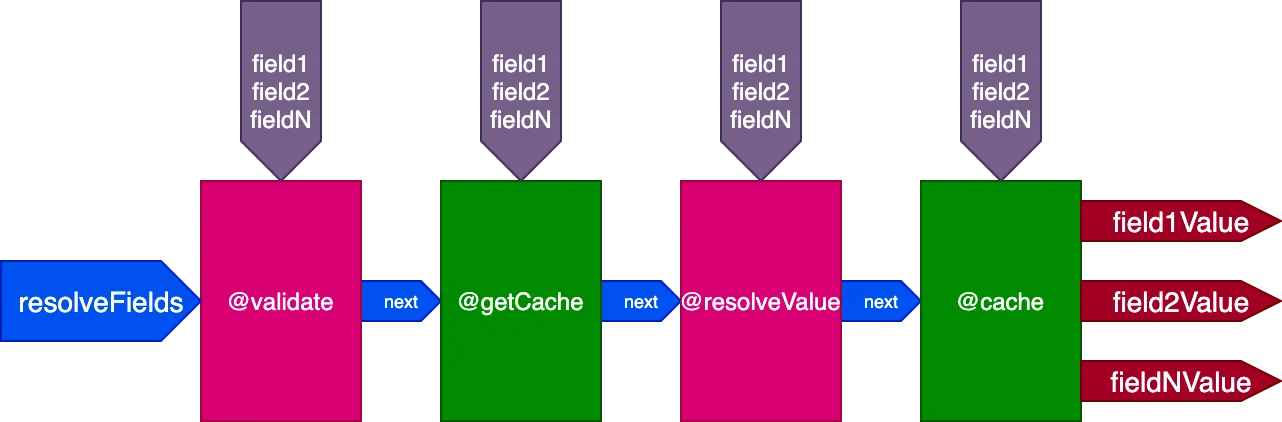
Bij het uitvoeren van deze query:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Zal de server 2 records ophalen en cachen. Vervolgens voeren we dezelfde query uit, maar toegepast op 4 records:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Bij het uitvoeren van deze 2e query waren de 2 records van de 1e query al gecacht, maar de andere 2 records niet. We zouden echter alle 4 records al gecacht moeten hebben om de vlag skipExecution te kunnen gebruiken. Het zou beter zijn als we de eerste 2 records uit de cache konden ophalen en alleen de andere 2 records konden oplossen.
Dus we updaten het ontwerp van de pipeline opnieuw. We laten de vlag skipExecution vallen en geven in plaats daarvan aan elke directive de lijst van object-ID's per veld door waar de directive moet worden toegepast, via een invoerobj fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}De variabele fieldIDs is uniek voor elke directive, en elke directive kan de instantie van fieldIDs voor alle directives in latere stadia aanpassen. Dan kan skipExecution granuleerbaar worden uitgevoerd op ID-voor-ID-basis, door simpelweg het ID te verwijderen uit fieldIDs voor alle aankomende directives in de stack.
De pipeline ziet er nu zo uit:
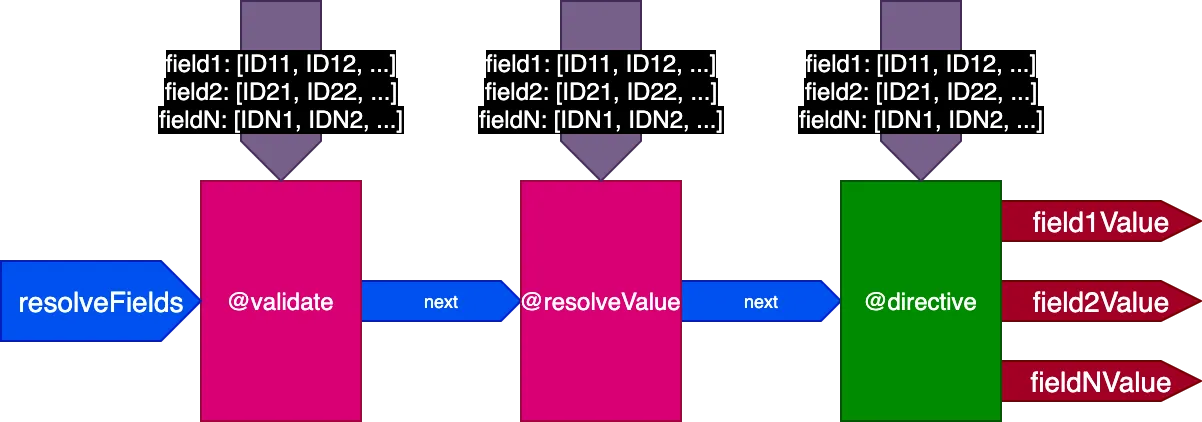
Toegepast op het vorige voorbeeld, ziet de pipeline er bij het uitvoeren van de eerste query die 2 records vertaalt als volgt uit:
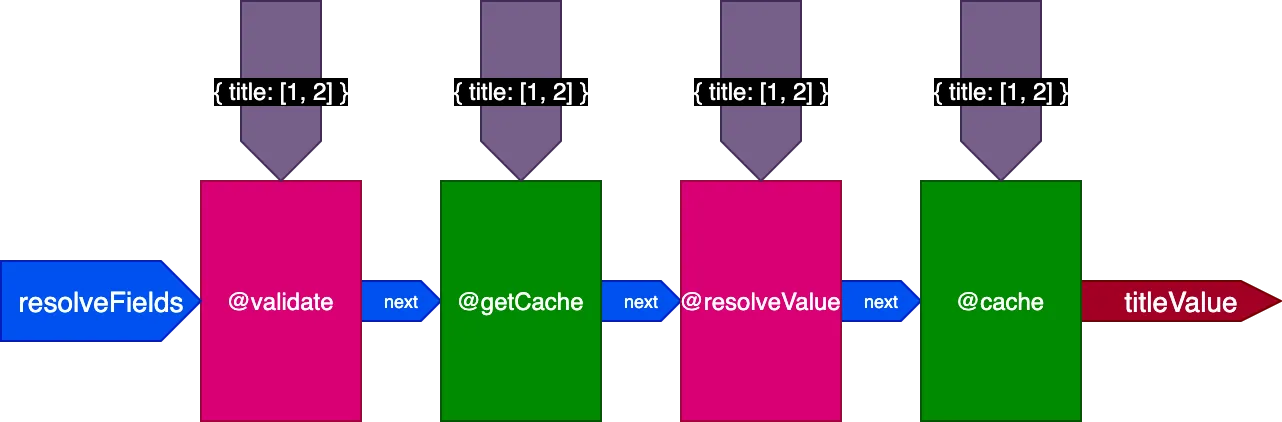
Bij het uitvoeren van de tweede query die 4 records vertaalt, ontvangt directive @getCache de ID's van alle 4 records, maar zullen zowel @resolveValueAndMerge als @cache alleen de ID's van de laatste 2 records ontvangen (die niet gecacht zijn):
Alles samenbrengen
Dit is het definitieve ontwerp van de directive-pipeline:
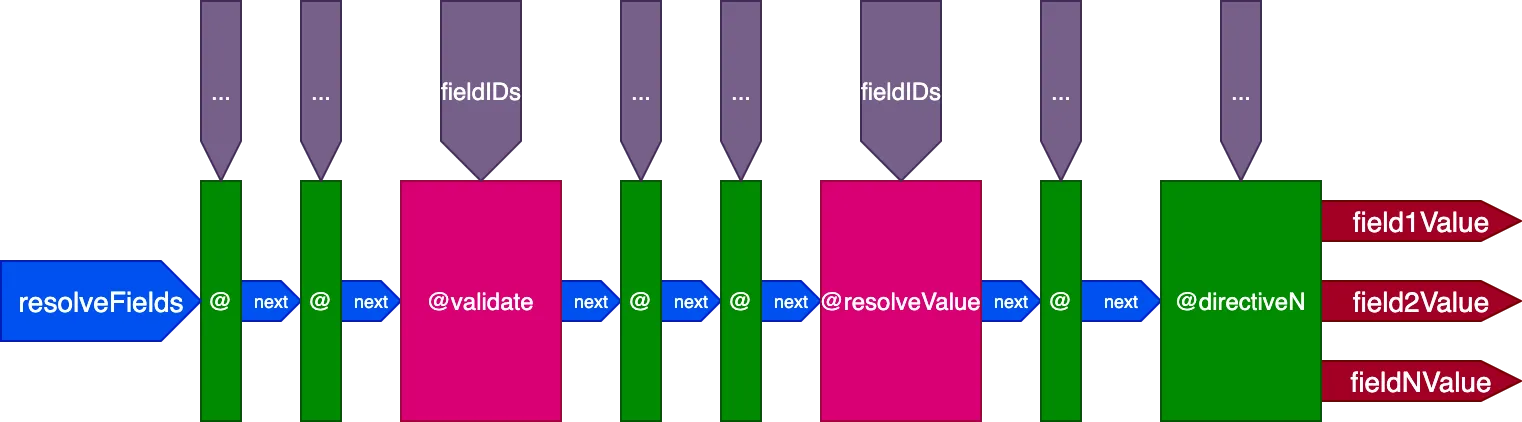
Samengevat zijn dit de kenmerken:
- Veld-resolvers worden aangeroepen vanuit de directive-pipeline, via directives
@validateen@resolveValueAndMerge - Directives kunnen in elk van de 5 slots worden geplaatst:
"beginning","before-validate","middle","after-validate"en"end" - Directives lossen meerdere velden op in één aanroep
- Één enkele pipeline bevat alle directives die betrokken zijn bij de query
- Elke directive ontvangt zijn eigen set ID's om per veld op te lossen via de variabele
fieldIDs - Directives kunnen de variabele
fieldIDsaanpassen voor alle directives in een later stadium van de pipeline