
Componenten gebruiken in plaats van grafen
Gato GraphQL gebruikt geen grafen om het datamodel te representeren. In plaats daarvan gebruikt het componenten.
Dit is geen onverwachte aanpak. Onder de titel Thinking in Graphs stelt het GraphQL-project (nadruk toegevoegd):
Grafen zijn krachtige hulpmiddelen voor het modelleren van veel verschijnselen uit de echte wereld, omdat ze lijken op onze natuurlijke mentale modellen en verbale beschrijvingen van het onderliggende proces. Met GraphQL modelleer je je bedrijfsdomein als een graaf door een schema te definiëren; binnen je schema definieer je verschillende soorten knooppunten en hoe ze met elkaar verbonden zijn/zich tot elkaar verhouden. Aan de clientkant creëert dit een patroon vergelijkbaar met objectgeoriënteerd programmeren: typen die verwijzen naar andere typen. Aan de serverkant, omdat GraphQL alleen de interface definieert, heb je de vrijheid om het te gebruiken met elke backend (nieuw of bestaand!).
De conclusie uit deze definitie is als volgt:
Ook al heeft het antwoord de vorm van een graaf, dat betekent niet dat data daadwerkelijk als een graaf wordt gerepresenteerd bij het verwerken ervan aan de serverkant. De graaf is slechts een mentaal model, geen daadwerkelijke implementatie.
Dit is goed nieuws, omdat het werken met grafen (of bomen) niet triviaal is. Componenten daarentegen zijn veel eenvoudiger te implementeren en bieden dezelfde voordelen.
Het datamodel vereenvoudigen via componenten
Het gebruik van componenten om de datastructuur aan de serverkant te representeren is optimaal wat betreft eenvoud, omdat het mogelijk maakt de verschillende modellen voor onze data samen te voegen in één structuur. In plaats van een flow zoals deze:
query bouwen om componenten te voeden (client) => data verwerken als graaf/boom (server) => data aan componenten doorgeven (client)
...zal onze flow er zo uitzien:
componenten (client) => componenten (server) => componenten (client)
Dit is haalbaar omdat het GraphQL-verzoek kan worden beschouwd als een datastructuur met een "componenthiërarchie", waarbij elk objecttype een component vertegenwoordigt, en elk relatieveld van het ene objecttype naar het andere een component vertegenwoordigt dat een ander component omhult.
Laten we een voorbeeld gebruiken om deze relatie van component naar GraphQL-query te visualiseren. Stel dat we de volgende "Uitgelichte regisseur" widget willen bouwen:
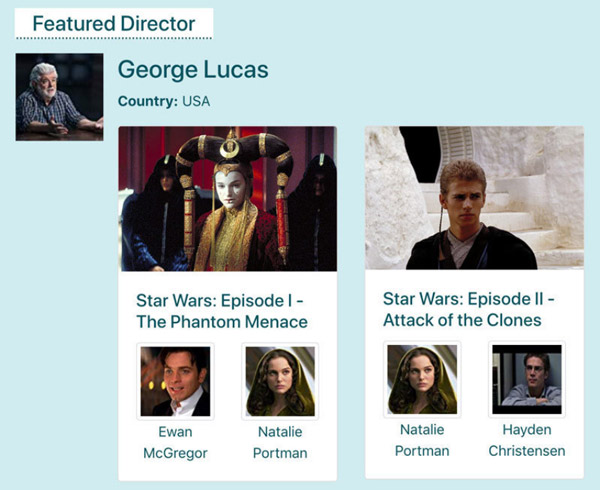
Met Vue of React (of een andere op componenten gebaseerde bibliotheek) zouden we eerst de componenten identificeren. In dit geval zouden we een buitenste component <FeaturedDirector> hebben (in rood), die een component <Film> omhult (in blauw), die zelf een component <Actor> omhult (in groen):
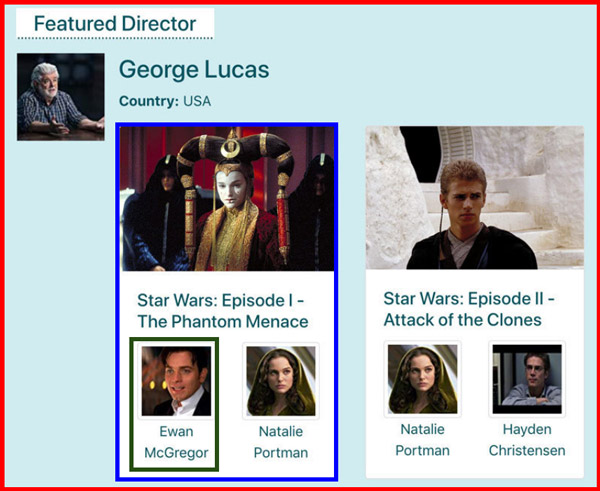
De pseudocode ziet er zo uit:
<!-- Component: <FeaturedDirector> -->
<div>
Country: {country}
{foreach films as film}
<Film film={film} />
{/foreach}
</div>
<!-- Component: <Film> -->
<div>
Title: {title}
Pic: {thumbnail}
{foreach actors as actor}
<Actor actor={actor} />
{/foreach}
</div>
<!-- Component: <Actor> -->
<div>
Name: {name}
Photo: {avatar}
</div>Vervolgens bepalen we welke data nodig is voor elk component. Voor <FeaturedDirector> hebben we name, avatar en country nodig. Voor <Film> hebben we thumbnail en title nodig. En voor <Actor> hebben we name en avatar nodig:
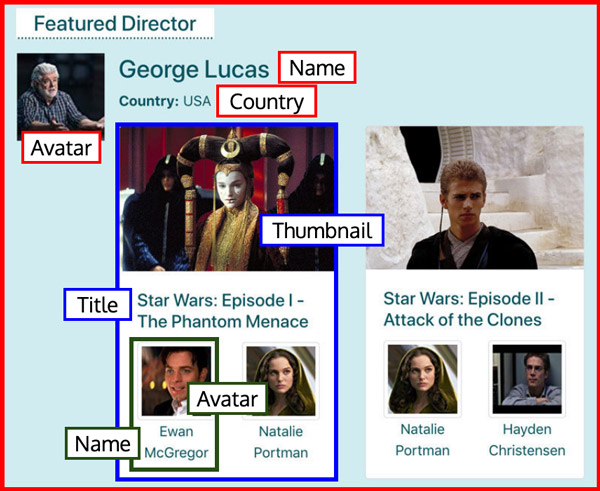
En we bouwen onze GraphQL-query om de benodigde data op te halen:
query {
featuredDirector {
name
country
avatar
films {
title
thumbnail
actors {
name
avatar
}
}
}
}Zoals te zien is, bestaat er een directe relatie tussen de bovenstaande componenthiërarchie en deze GraphQL-query.