
De volgorde van veldresolutie manipuleren
Het doel van de @export-directive die door Multiple Query Execution wordt geleverd, is het exporteren van de waarde van een veld (of een set velden) naar een variabele, om elders in de query te gebruiken.
Deze directive zou niet werken als het uitlezen van de variabele plaatsvindt vóórdat de waarde naar de variabele is geëxporteerd. Daarom moet de engine een manier bieden om de uitvoeringsvolgorde van velden te beheren.
Gato GraphQL biedt een manier om de uitvoeringsvolgorde van velden via de query zelf te manipuleren. De engine laadt gegevens iteratief voor elk type — eerst worden alle velden van het eerste type dat in de query voorkomt opgelost, dan alle velden van het tweede type dat voorkomt, enzovoort totdat er geen typen meer te verwerken zijn.
Neem bijvoorbeeld de volgende query met objecten van het type Director, Film en Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...wordt door de GraphQL-engine in deze volgorde opgelost:

Als een type na verwerking opnieuw in de query wordt gebruikt om nog niet geladen gegevens op te halen (bijvoorbeeld uit aanvullende objecten of aanvullende velden van reeds geladen objecten), wordt het type opnieuw aan het einde van de iteratielijst toegevoegd.
Als we bijvoorbeeld ook het veld preferredDirector van Actor opvragen (dat een object van het type Director retourneert), zoals hier:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...verwerkt de GraphQL-engine de query in deze volgorde:

Laten we bekijken hoe dit uitpakt bij het uitvoeren van @export in één enkele query. Voor onze eerste poging maken we de query zoals we dat normaal doen, zonder na te denken over de uitvoeringsvolgorde van de velden:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Als je de query uitvoert, geeft die dit antwoord:
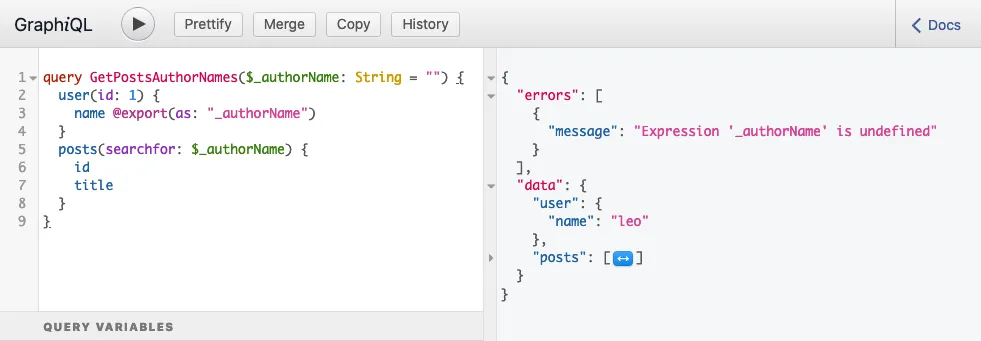
...dat de volgende fout bevat:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Deze fout betekent dat variabele $authorName op het moment dat die werd uitgelezen nog niet was ingesteld; de waarde was undefined.
Laten we bekijken waarom dit gebeurt. Eerst analyseren we welke typen in de query voorkomen, hieronder als commentaar toegevoegd:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Om de typen te verwerken en hun gegevens te laden, voegt de data-loading-engine het querytype Root toe aan een FIFO-lijst (First-In, First-Out), waardoor [Root] de beginlijst is die aan het algoritme wordt doorgegeven, waarna het sequentieel over de typen itereert, als volgt:
| # | Bewerking | Lijst |
|---|---|---|
| 0 | FIFO-lijst voorbereiden | [Root] |
| 1a | Het eerste type van de lijst verwijderen (Root) | [] |
| 1b | Alle velden verwerken die zijn opgevraagd van het type Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Hun typen ( User en Post) aan de lijst toevoegen | [User, Post] |
| 2a | Het eerste type van de lijst verwijderen (User) | [Post] |
| 2b | Het veld verwerken dat is opgevraagd van het type User:→ name @export(as: "authorName")Omdat het een scalair type is ( String), hoeft het niet aan de lijst te worden toegevoegd | [Post] |
| 3a | Het eerste type van de lijst verwijderen (Post) | [] |
| 3b | Alle velden verwerken die zijn opgevraagd van het type Post:→ id→ titleOmdat dit scalaire typen zijn ( ID en String), hoeven ze niet aan de lijst te worden toegevoegd | [] |
| 4 | Lijst is leeg, iteratie eindigt. |
Hier zien we het probleem: @export wordt uitgevoerd in stap 2b, maar werd uitgelezen in stap 1b.
Dit is het moment waarop we de uitvoeringsstroom van de velden moeten beheersen. De geïmplementeerde oplossing bestaat eruit het uitlezen van de geëxporteerde variabele te vertragen, wat bereikt wordt door kunstmatig het veld self van het type Root op te vragen.
Het veld self retourneert, zoals de naam al aangeeft, hetzelfde object; toegepast op het Root-object retourneert het datzelfde Root-object. Je vraagt je misschien af: "als ik het root-object al heb, waarom zou ik het dan opnieuw ophalen?". Omdat het algoritme van de engine dit nieuwe verwijzing naar Root dan aan het einde van de FIFO-lijst moet toevoegen, en we de opgevraagde velden bewust vóór of na elk van deze iteraties kunnen verdelen.
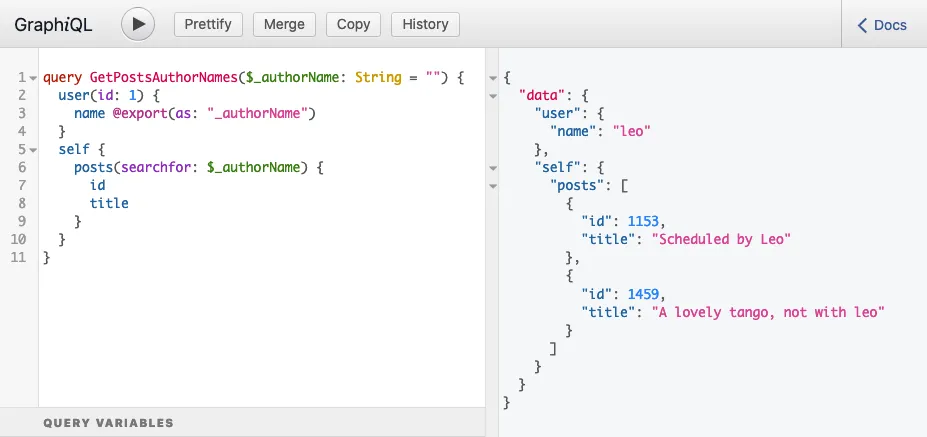
Daarom is het veld posts(filter:{ search: $authorName }) in de bovenstaande query binnen een self-veld geplaatst, en levert het uitvoeren van de query het verwachte antwoord op:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Laten we de volgorde bekijken waarin typen worden verwerkt voor deze query, om te begrijpen waarom die goed werkt:
| # | Bewerking | Lijst |
|---|---|---|
| 0 | FIFO-lijst voorbereiden | [Root] |
| 1a | Het eerste type van de lijst verwijderen (Root) | [] |
| 1b | Alle velden verwerken die zijn opgevraagd van het type Root:→ user(by: {id: 1})→ selfHun typen ( User en Root) aan de lijst toevoegen | [User, Root] |
| 2a | Het eerste type van de lijst verwijderen (User) | [Root] |
| 2b | Het veld verwerken dat is opgevraagd van het type User:→ name @export(as: "authorName")Omdat het een scalair type is ( String), hoeft het niet aan de lijst te worden toegevoegd | [Root] |
| 3a | Het eerste type van de lijst verwijderen (Root) | [] |
| 3b | Het veld verwerken dat is opgevraagd van het type Root:→ posts(filter:{ search: $authorName })Zijn type ( Post) aan de lijst toevoegen | [Post] |
| 4a | Het eerste type van de lijst verwijderen (Post) | [] |
| 4b | Alle velden verwerken die zijn opgevraagd van het type Post:→ id→ titleOmdat dit scalaire typen zijn ( ID en String), hoeven ze niet aan de lijst te worden toegevoegd | [] |
| 5 | Lijst is leeg, iteratie eindigt. |
Nu zien we dat het probleem is opgelost: @export wordt uitgevoerd in stap 2b, en wordt uitgelezen in stap 3b.
Multiple Query Execution doet precies dit bij het ontkoppelen van queries: het converteert het GraphQL-document door self-velden toe te voegen, zodat de velden in elke operatie pas worden uitgevoerd nadat alle velden in alle vorige operaties zijn opgelost.